Do Androids Dream of Electric Sheep?
 |
| Google's deep dream: counting sheep in the clouds |
Over the last few weeks, google open sourcing it's "Deep Dream" has taken the internet by storm, with a stream of images ranging from transformation of images to a beautiful impressionist style, to a nightmarish acid trip of dogs, spiders, and slugs, to seemingly conjuring believable images out of thin air. It has captured the imagination of the public, as we seemingly are reaching for the dawn of a new era of thinking machines, that can understand what we say, can look at things and know what they are, and can even imagine things that don't exist.
 |
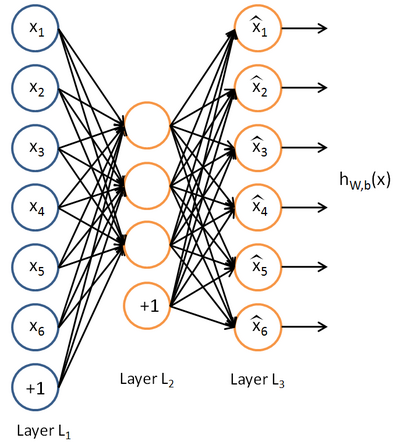
| A Simple feed forward neural network |
But how does this work under the hood? The great advance in deep learning over the past decade has taken an old idea (neural networks), and extended it to extream depths. A neural network is composed of layers of neurons, with one side consisting of input neurons (say an input for each pixel in an image), some hidden layers that transform those inputs into an intermediate representation of features and patterns discovered about the input, and a layer of output neurons, which represent a classification of some thing you are trying to recognize. Each connection between two neurons carries a multiplier "weight", to scale the contribution from the incoming connection when it reaches the next layer. Each neuron in the hidden layer sums up all the contributions from the incoming connections, and applies a non-linear "activation" function that tends to produce values either close to 1 or 0. The weights between connections are adjusted during a training period, where a series of images are presented to the network, and the weights are tweaked every time the network produces an incorrect classification. Eventually, the network reaches a point where no further improvements can be discovered, and the training ends. This isn't always the best set of weights to determine the class, but it can be a good approximation.
In the simple example above there is a single hidden layer, but multiple hidden layers can exist, each layer creating more complex representations than the one before it. In the first hidden layers, features like edges and corners are discovered, forming the input for the next hidden layers. Later hidden layers discover individual features, such as eyes or noses. The final layer combines those discovered features to recognize whole faces, or whatever category you are trying to discover in your dataset. Each layer is trained in a process called "backpropagation", which involves looking at each individual weight, and peturbing it to see if it makes the overall classification more or less accurate. Then the weight is bumped in the direction that makes it more accurate.
A problem occurs in training these networks with many hidden layers. Layers close to the output of the network have a dominant impact on the outcome of the training. Layers towards the input make diminishing contributions. So unless the hidden layers near the front of the network start out at good values, the network tends to converge to a local minimum that is not a good representation of the knowledge.
 |
| Autoencoder |
About a decade ago, researchers developed a new technique for doing a greedy training of each layer independent of the later layers in the network, called an autoencoder. Here, weights are chosen so that the incoming layer could be reproduced as the input to the next layer, but where the hidden layer is smaller than the original layer that was fed into it... you can think of this as a compression of the original knowledge. This is important because the network is forced to only capture the most critical features of the original inputs, so each hidden neuron must capture a specific concept to be effective. Later, this was done by enforcing a sparseness constraint for the hidden layer, where the network could only fire a small percentage of nodes in the hidden layer for each input. This pre-training step could be used to pick a good starting point for backpropagation, and in the end we can have very deep neural networks.
 |
| Animals in the stars |
One of the problems with neural networks is there tends to be an opaqueness as to what these weights are actually encoding in a hidden neuron. This is where "deep dreaming" comes into play. Each neuron in the network will output numbers closer to 1 when it is excited by the input, and numbers closer to 0 otherwise. So the trick is to take the input layer of a network, and tweak the values to maximise the excitement for a given neuron that we want to find out what it does. We also must use a constraint that makes the pixels of an image conform to a normal spectrum of input. As this process is repeated over and over, new features in the image emerge. In the image above, the network sees animals in a nebula, and after repeated iterations, you see these faces too.
 |
| before |
 |
| after |
Of course, any curious software developer wants to play around with the code to try it for himself. While google has open sourced the code to achieve this, there are a number of dependencies that need to be included, and I ended up with conflicting versions during the install. The best solution I found was to use a docker image that someone provided the community. The one conclusion I seem to have made is androids don't dream of electric sheep. They dream about dogs.


Comments
Post a Comment