Skip to main content
Search
Search This Blog
The Bleeding Edge Machine
Posts
Showing posts from 2013
Show all
August 26, 2013
Nokia 1020
August 17, 2013
A Heuristic for Ultimate Tic Tac Toe
May 23, 2013
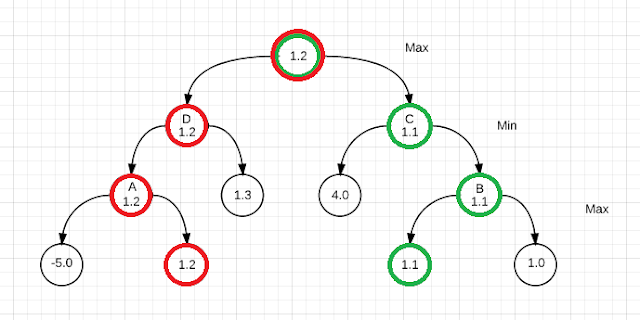
probabilistic alpha beta search
May 05, 2013
2013 Google Code Jam Round 1B
April 27, 2013
2013 Google Code Jam Round 1A
April 13, 2013
Google Code Jam Qualification Round
April 08, 2013
A fixed capacity cache with an LRU eviction policy in C#
March 07, 2013
Lessons from Sim City Limited
March 02, 2013
Google Code Jam Prep
February 24, 2013
Google Code Jam 2013
February 14, 2013
Scalatron
February 09, 2013
Beginning a model for emergent intelligent behavior
February 03, 2013
Facebook Hacker Cup 2013 Round 1 Problem 1
January 30, 2013
Facebook Hacker Cup 2013
Newer Posts
Older Posts
Home